RECON
Mass, heat and momentum balancing software with data reconciliation
Description
RECON is a comprehensive interactive software for modeling (mass, energy and momentum balancing, thermodynamic calculations, etc.) of complex chemical and power plants on the basis of measured or otherwise fixed data. It is designed primarily for the validation of data, which has been obtained from operating processes but can be used also for simulation of plant’s behavior under changed conditions. RECON can be also used for classical balancing in the stage of the process design.
RECON can be used in two operating modes:
- Data Validation and Reconciliation (DVR) mode. In this case models are solved on the basis of measured or otherwise set process data (flows, temperatures, etc.) to reconcile redundant data, calculate unmeasured process variables and identify model parameters (heat transfer coefficients, efficiencies, etc.).
- Simulation mode predicting plant’s behavior on the basis of models identified in the preceding DVR step.
In practice, RECON’s operation can be switched between these two modes of operation for updating models and using them for predicting plant’s behavior, optimization or answering “What if?” queries.
What is data reconciliation?
Reconciliation is a method for extracting all information present in plant data. Reconciliation is based on statistical adjustment of redundant process data to obey laws of nature (mass and energy conservation laws). Results are enhanced by calculated unmeasured variables. As a result, a new consistent more precise data set is obtained. Moreover, data reconciliation serves as a basis for other important activities:
- Finding confidence intervals for results (error propagation analysis)
- Detection and elimination of gross measurement errors
- Measurement planning and optimization.
RECON can be used to treat measured data before its further usage for other purposes (simulation, optimization, control, ...). Brief survey of reconciliation theory is contained in Recon's User Manual of the application.
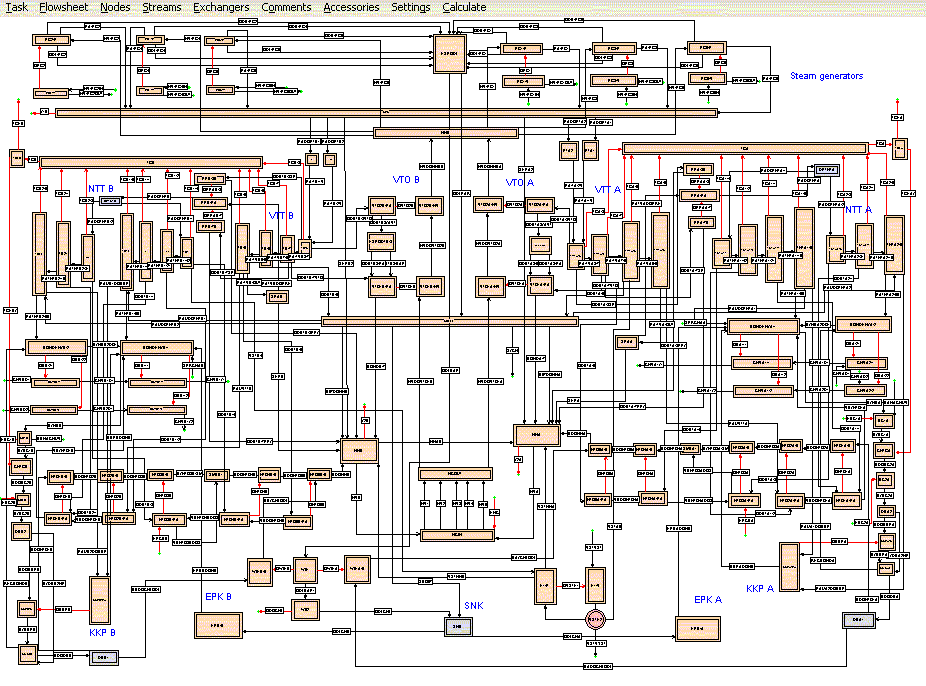
Graphical User Interface of RECON
Main Features
RECON is a PC oriented software with user friendly facilities. Problems (tasks) are defined interactively in the graphical user interface. RECON is aimed at single or multi-component material and energy balancing of complex systems at steady or unsteady (dynamic) state, without or with chemical reactions (reactor balancing). It is also capable to perform momentum balancing based on hydraulic calculations of flow in pipeline systems. RECON reconciles measured flow rates, concentrations, temperatures and other process variables and calculates unmeasured variables. Problem (task) is commonly defined by creating a process flowsheet and defining process variables like flow rates, temperatures, pressures, etc. The flowsheet comprises nodes, mass and energy streams, and heat exchangers. Users are also allowed to complete (or even replace) balancing model by their own equations.
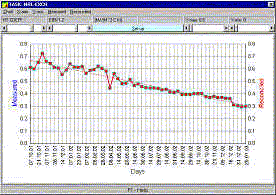
Monitoring of a heat transfer coefficient in RECON
Typical tasks solved by RECON
- mass and energy balances of chemical and refinery plants
- natural gas processing
- distribution systems of utilities
- detailed balancing of chemical plants (multi-component systems with chemical reactions)
- monitoring industrial heat exchange systems (crude preheat trains and similar systems)
- balancing steam systems
- monitoring and on-line thermodynamic analysis of power generation systems (turbine efficiencies, low and high pressure preheats, condenser heat transfer, etc.)
- combustion processes (industrial furnaces, coal and gas fired boilers)
- balancing water treatment in power plants (softening, demineralization ... )
- power and heat cogeneration systems including sea water desalination plants
- flow of liquids and gases in pipes and pipeline systems including their hydraulics
- detailed mass and energy balance of nuclear plants (primary and secondary circuits, advanced assessment of nuclear reactor power)
Variables
Typical process variables are: Flowrates, concentrations, temperatures, pressures, steam wetnesses, etc. The following information on task variables must be specified:
- Classification of variables (measured, unmeasured, fixed)
- Values of measured and fixed variables
- Estimates (guesses) of unmeasured variables (for nonlinear problems only)
- Uncertainty (Maximum errors or standard deviations) of measured variables (and their covariances, if inevitable).
Capabilities
- Data import and pre-processing
- Calculation of unmeasured variables
- Reconciliation of redundant measured variables
- Analysis of input data as concerns its consistency
- Confidence intervals of results
- Statistical analysis focused on detection and identification of gross measurement errors
- Detailed classification of variables (redundant / non-redundant, observable / non-observable)
- Measurement placement optimization
- Parametric sensitivity
- Database of historical data useful for monitoring operating plants
- Reporting module based on user-defined templates in MS Excel
- Monte Carlo simulation
- Data mining.
RECON for Data Validation and Reconciliation consist of 5 parts:
- Configuration of models in GUI
- Calculation engine which is optimized as concerns speed and memory requirements. 2 methods of solution are available: Successive Linearization and Sequential Quadratic Programming. A special feature of RECON is the existence of the calculation engine also in the form of an ActiveX object which can be called from customer's proprietary software. In this way a customer can fully manage data processing
- Recon Manager for configuring and coordinating data processing
- Database and files containing Metadata (data about models, users, )
- Database of operational data. This can be either standalone for RECON (Access, Oracle or MS SQL Server) or fully integrated with customer's databases or historians (PI, PHD, InSQL, AIM*, Oracle, MS SQL Server, ) - this solution has important advantages.
Operational data can be entered manually or imported from 1 or more other sources (historians, databases, Excel or text files).
Aside of this software package there exist two autonomous Recon modules:
RecSim – module for simulation (creation of model variants, simulation and What if? Queries)
ErrMan – program for management of Gross Errors treatment in the case Recon on-line use.
Data pre-processing
Imported data can be pre-processed on the basis of several techniques (limits on input variables, limits on control variables). There is also a Basic-like editor for general data pre-processing calculations.
User defined equations
Aside of problem configuration in the Recon's GUI the user can define his own model equations. There is a Basic-like editor for writing new model equations. User can use conditional programming with logical variables. It is possible to use in equations complex thermodynamic functions, physical properties, etc. User defined equations can be used also for defining model inequalities.

Editor of User Defined Equations
Chemical reactors
Chemical reactors can be modeled by 2 ways: The standard method uses chemical reactions (stoichiometric coefficients) stored in Recon's reaction bank. Sometimes reactions in the system are not well known (e.g. burning of coal). In this case user can use the second method based on the so-called reaction invariant chemical reactor. In this case only the knowledge of atomic composition of components is required.
Gross errors treatment
There are 3 steps of Gross Errors (GE) treatment:
1. detection
2. identification
3. elimination
GE detection - finding the GE presence. The data quality is continuously monitored via the Status of data quality (SDQ). This variable should be under normal situation below 1. Values of SDQ above 1 signal the presence of some Gross Error (either an instrument or model error). SDQ is based on so-called Global chi-square test testing the value of the least square function minimized during DR.
There are several methods available for GE identification:
2. Successive elimination of suspect measurements. Suspect variables from the step 1 are automatically set one by one as unmeasured. Variables with the largest decrease of SDQ are suspect.
3. Measurement credibility. Values calculated in the step 2 are compared with limits set on variables. If the calculated value is not probable or feasible, this suspect is excluded from the set of suspects
4. Nodal test. In the case of mass balance the imbalances around individual nodes or their combinations can be statistically tested. Streams around suspect nodes are suspect. This method is suitable also for finding the frequent model errors - leaks or neglected mass accumulation.
5. Covariance matrices of adjustments are available for detailed analysis of the gross error identification problem.
The steps in GE identification are semi-automatic. All this serves as a Decision Support System for the user.
GE elimination. We do not recommend and support the automatic elimination of gross errors. This function offered by some providers of DR software frequently leads to wrong decisions. Good data can be deleted and the wrong ones remain with formally good balances. This opinion is supported also by balancing theory. GE elimination should be done by the DR system administrator with further actions (instrumentation repair etc.).
Data mining
A long term use of RECON enables one to create a historical database of validated process data. Such database represents an invaluable source of information which can be utilized in many areas (creation of empirical models, optimization, etc.). Such activities are usually denoted as data mining.
The new data mining module of RECON enables one to analyze easily large data sets and to find hidden relationships among data. By a few key strokes a user can easily create multiple regression models among process variables. Attention is also paid to the statistical analysis of process data and to removal of outliers.
Process data driven simulation
Besides the main Recon model (the Base Case) there can be one or more model variants. The individual variants differs in inputs and outputs of the calculation This feature enables one to switch Recon between the data reconciliation and validation mode to the simulation mode. This can be done either manually or automatically.
What if? Queries
The Process data driven simulation is the basis of the What if? Queries module of Recon. In this way operators can easily see what will happen if they will change some control variable. Data from the process are imported and parameters of the process model are identified. Then the operator enters the change of one or more process variables and runs the simulation. After that he can see in few seconds the influence of changes of inputs on outputs.

The opening screen for What if? Queries
MonteCarlo simulation
Statistical theory of data reconciliation is exactly valid for linear models only. Any use of statistical theory to general nonlinear models is limited to a small neighborhood of the final solution. In practice this means that standard deviations of measurement errors should be "small" enough to justify acceptable validity of results (reconciled values, confidence intervals, gross errors detection, etc.). Analytical solution of this problem is not feasible in practice.
The only way how to tackle this problem is the Monte Carlo simulation. This solution is based on repeated simulation of the measurement process. The starting point is an errorless data set (a base case). Individual "measured" data sets are generated by adding random errors to the base case data. In this way a real measurement is simulated many times with the following data reconciliation. Results can be statistically evaluated and compared with theoretical values.
Pinch technology and heat integration
Recon heat balance models can provide also information directly applicable for deeper analysis of such systems by the Pinch Technology, Heat Integration, using Heat Pumps, etc. Necessary validated data for such activities are available in the form of MS Excel workbooks.


Reporting engine
RECON enables one to create reports in the MS Excel environment. The solution is based on Excel templates prepared by users. These templates contain links to RECON's database. In this way any user can define unlimited number of report templates which can be later used for generation of reports. The complexity of these reports is limited by Excel's capabilities only. Reports can be generated either in the interactive way by a user or automatically at a pre-defined time.
RECON's connectivity
RECON can be connected to process data information systems based on the Oracle, MS SQL, PI System, Industrial SQL server, PHD, AIM*, Exaquantum, OPH and MS Access databases as well as to MS Excel, .DBF or .TXT files.
How to set up data sources is shown in Recon Data connectivity video.
RECON's physical property database
RECON contains the following databases of physical properties:
- The IAPWS IF 97 database of properties of steam ad water
- Properties of hydrocarbons and other chemicals according to API procedures
- SRK equation of state to estimate gas compressibilities
- Critical parameters of components for density and viscosity calculations of gaseous mixtures
- User defined physical property models
RECON languages
- Czech
- English
- German
- Spanish
- Russian
Running RECON
RECON can be run in the following modes:
- Interactive solving of one task
- On-line monitoring of industrial processes
- Automatic processing of historical data
- Simulation and “What if?” Queries via Web services
- As ActiveX DLL called from other programs.
Hardware Requirement
RECON is the 32 bit MS Windows application which can be installed on any PC or server operating under MS Windows 95 or higher (XP, Vista, Windows 7: 32-bit or 64-bit processor, Windows 10: 32-bit or 64-bit processor). The minimum recommended processor is Pentium with RAM 128 MB.
Available versions
| Version | Mass balance | Energy balance | Momentum balance | User-defined equations | DB connectivity | Active X object (DLL) |
|---|---|---|---|---|---|---|
| Lite* | x | x | x | x | ||
| Academic** | x | x | x | x | ||
| Full | x | x | x | x | ||
| Professional | x | x | x | x | x | x |
| Trial*** | x | x | x | x | x |
| * max 50 nodes, 100 streams, 10 heat exchangers, 10 components and 20 user-defined equations |
| ** for non-commercial purposes only |
| *** valid for 1 month |
Demo Examples
Recon contains about 50 Demo examples of various models. Here is prepared a detailed description of Mass & Component Balance and Heat & Energy Balance Demo Examples.